Answers>Learn about reliability & uptime>What is high availability in blockchain infrastructure?
What is high availability in blockchain infrastructure?
// Tags
high availability blockchainblockchain uptime
TL;DR: High availability (HA) refers to systems designed to stay online and responsive with minimal downtime, even when individual components fail. In blockchain infrastructure, HA means your RPC endpoints, nodes, and data pipelines keep serving requests reliably, typically targeting 99.9% uptime or higher. Why Uptime Matters More Than You Think
When a traditional web app goes down, users see an error page. When blockchain infrastructure goes down, the consequences can be far more severe. Missed transactions, stale data, failed trades, and unprocessed events don't just frustrate users. They cost real money.
Consider a DeFi trading bot that relies on an RPC endpoint to submit transactions. If that endpoint goes offline for even 30 seconds during a volatile market move, the bot misses the window entirely. Or think about a wallet app that can't fetch balances because its node provider is experiencing an outage. Users don't know if their funds are safe, and your support queue explodes.
High availability is the engineering discipline that prevents these scenarios. It means designing systems where no single failure takes everything offline.
What is high availability in blockchain?
High availability in blockchain is the practice of keeping nodes, RPC endpoints, and data pipelines online and responsive even when individual components fail. Instead of trusting one node or one region, a highly available setup spreads work across redundant components so a single failure never takes the whole service down. It depends heavily on healthy, synced nodes, which is why node reliability and automatic failover are core building blocks.
How High Availability Works
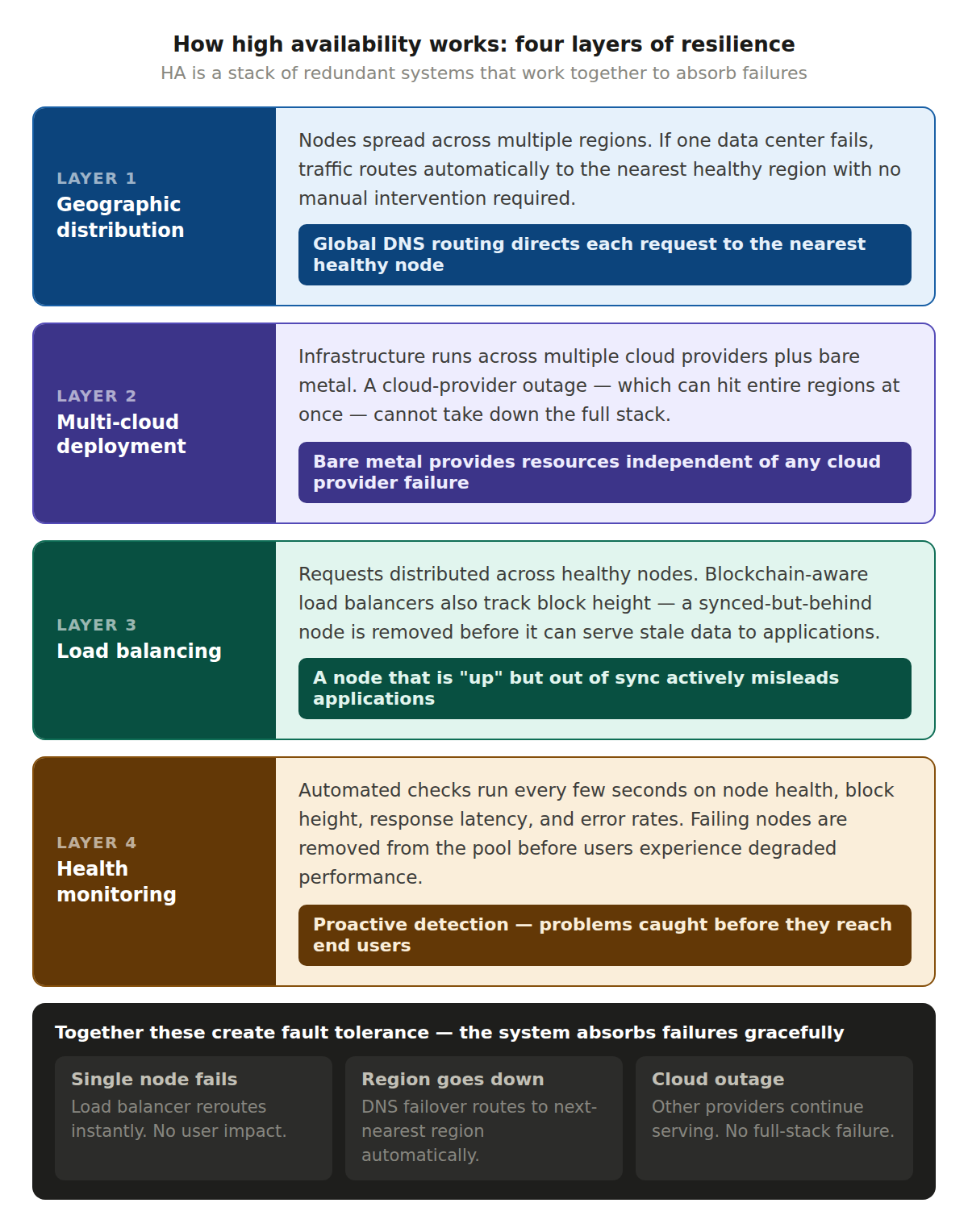
At its core, HA is about eliminating single points of failure. Instead of relying on one server, one data center, or one cloud provider, a highly available system distributes its workload across multiple redundant components.
In blockchain infrastructure, this typically involves several layers. The first is geographic distribution, where nodes are spread across multiple regions so that if one data center has an issue, traffic automatically routes to the nearest healthy alternative. The second is multi cloud deployment. Running on more than one cloud provider (and sometimes bare metal) ensures that a cloud specific outage doesn't take down your entire stack. The third is load balancing, which distributes incoming RPC requests across a pool of healthy nodes, automatically routing around any that are slow or unresponsive. The fourth is health monitoring, where automated systems continuously check node health, block height, and response times, flagging problems before they affect users.
These components work together to create what engineers call fault tolerance. The system absorbs failures gracefully instead of falling over.
Measuring Availability
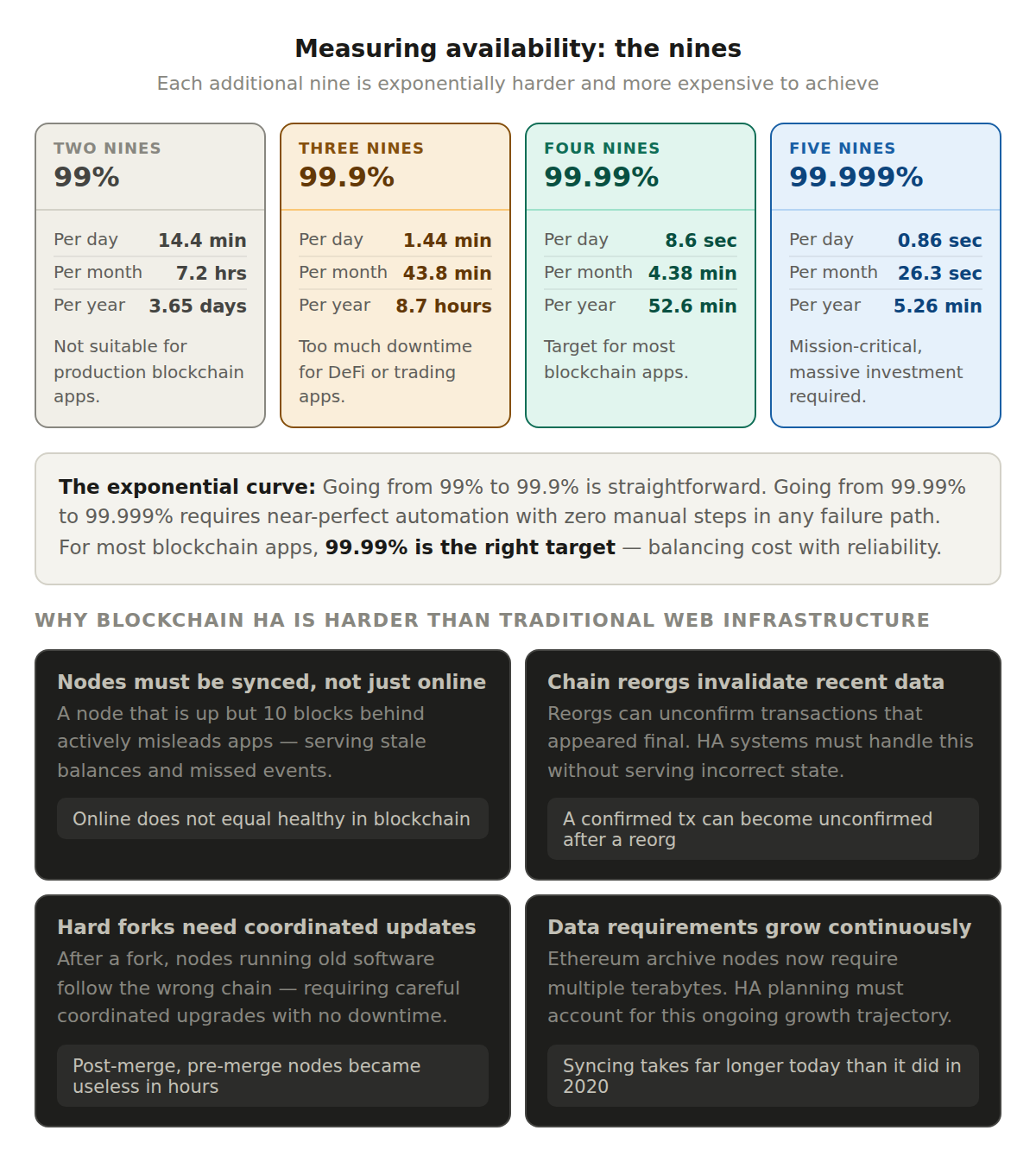
Availability is usually expressed as a percentage of uptime over a given period. You'll often hear terms like "three nines" (99.9%) or "four nines" (99.99%).
Here's what those numbers actually mean in practice. At 99.9% uptime, you get roughly 8.7 hours of downtime per year. At 99.99%, that drops to about 52 minutes per year. At 99.999% (five nines), you're looking at just over 5 minutes of downtime for the entire year.
Each additional nine is exponentially harder to achieve and requires significantly more investment in redundancy, monitoring, and automation. For most blockchain applications, 99.99% is the target that balances cost with reliability.
What uptime percentage should you target?
Uptime targets are described in "nines." Each additional nine cuts allowed downtime dramatically and costs more to achieve. The table shows what each level means in practice over a full year.
Uptime
Name
Downtime per year
99.9%
Three nines
About 8.7 hours
99.99%
Four nines
About 52 minutes
99.999%
Five nines
Just over 5 minutes
How is high availability different from fault tolerance?
People use these terms interchangeably, but they are not the same. High availability aims to minimize downtime, accepting brief interruptions during failover. Fault tolerance aims for zero downtime by running fully redundant components in parallel. Most blockchain teams pursue high availability because it delivers strong uptime at a reasonable cost.
Traditional web services can simply spin up more servers behind a load balancer. Blockchain infrastructure is more complex because nodes need to stay in sync with the network. A node that falls behind on block height is essentially useless, even if it's technically "online."
Blockchain also introduces unique failure modes that don't exist in traditional infrastructure. Chain reorgs can temporarily invalidate recent data. Network upgrades or hard forks require coordinated node updates. Different client implementations can behave differently under load. And the data itself is constantly growing, which means storage and sync requirements increase over time.
All of this makes blockchain HA more nuanced than simply running a load balancer in front of a cluster of servers. It requires deep protocol awareness and continuous operational investment.
How do you design a highly available RPC setup?
A resilient setup combines several techniques: distribute nodes across regions and providers, put a load balancer in front of a pool of healthy nodes, monitor block height and latency so unsynced nodes are removed automatically, and keep a backup provider ready for failover. From the application side this is still a single RPC endpoint, but behind it sits the redundancy that keeps you online. Continuous monitoring of your blockchain infrastructure is what makes automatic routing decisions possible.
How Quicknode Approaches High Availability
Quicknode runs infrastructure across 14+ regions on multiple cloud and bare metal providers. Every RPC request is routed to the closest healthy node through global DNS based routing, and the system continuously monitors block height, latency, and error rates to ensure requests always land on nodes that are both online and fully synced.
For teams that need even stronger guarantees, Quicknode offers dedicated clusters with private, isolated infrastructure and guaranteed uptime SLAs.
What does high availability mean for an RPC endpoint?
It means the endpoint keeps answering requests even when individual nodes, regions, or providers fail. Traffic is routed to healthy, synced nodes automatically, so your application sees consistent uptime instead of errors.
What uptime is good for blockchain infrastructure?
Most production applications target 99.99% uptime, which allows about 52 minutes of downtime per year. Reaching 99.999% is possible but costs significantly more in redundancy and automation.
Why is high availability harder for blockchain than web apps?
Nodes must stay in sync with the network, so a node that is online but behind on block height is still unusable. Blockchain-specific events also complicate things, which we cover in common blockchain failure modes.
How do chain reorgs affect availability?
A reorg can temporarily invalidate recent data, so highly available systems wait for confirmations or handle reorgs explicitly. See what a blockchain reorg is for details.
Does high availability remove the need for a backup provider?
No. A single provider's high availability reduces risk, but keeping an independent backup provider protects you against provider-wide incidents and is a common part of a resilient design.