Answers>Learn about indexing & blockchain data>RPC vs indexing: What’s the difference?
RPC vs indexing: What’s the difference?
// Tags
RPC vs indexingwhen to use indexer
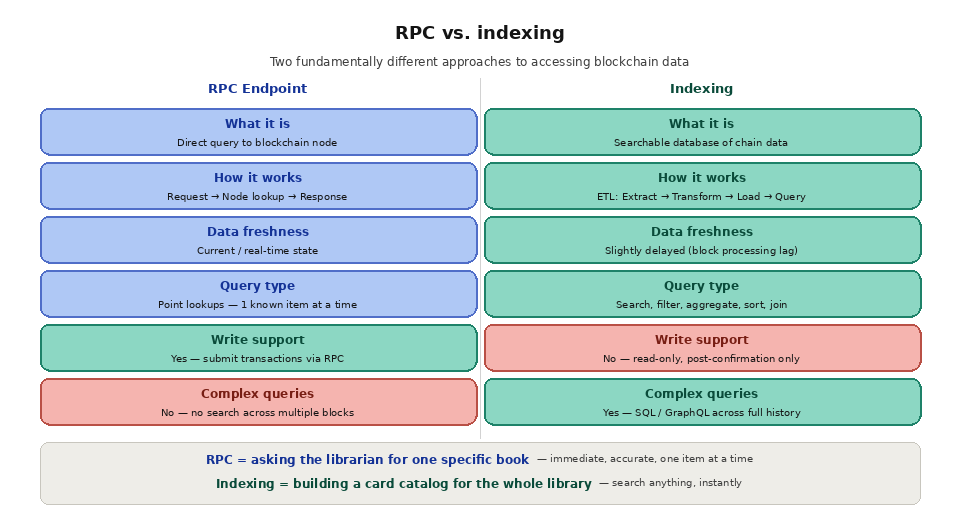
TL;DR: RPC and indexing are two fundamentally different approaches to accessing blockchain data. RPC endpoints let you query the current state of the blockchain in real time, one request at a time. Indexing extracts, transforms, and stores blockchain data in a searchable database so your application can run complex queries across historical records. RPC is like asking a librarian to find one specific book. Indexing is like building a card catalog for the entire library. Most production applications need both.
The Simple Explanation
Every blockchain application needs data. A wallet needs account balances. A DeFi dashboard needs token prices and liquidity pool states. An NFT marketplace needs ownership records and transaction history. An analytics platform needs aggregate metrics across thousands of contracts and millions of transactions. The question is how to get that data from the blockchain into your application.
RPC endpoints are the blockchain's native interface. When your application sends a JSON-RPC request to a node, it is asking a direct question about the blockchain's current or recent state: what is this wallet's balance right now, what happened in this specific transaction, what does block number 20,000,000 contain. The node looks up the answer and returns it. RPC is immediate, accurate, and straightforward for point lookups. But it has a critical limitation: RPC methods are designed for fetching specific, known data, not for searching or aggregating across the chain. There is no RPC method for "find all transactions from this wallet in the last 30 days" or "show me the top 10 liquidity pools by volume."
Indexing fills this gap by building a searchable database on top of raw blockchain data. An indexer reads every block as it is produced, decodes transactions and event logs, transforms the raw data into structured records, and writes those records to a database with proper indexes. Once indexed, your application can query the data using SQL, GraphQL, or any other query language your database supports. Complex filters, aggregations, sorting, joins, and full-text search all become possible.
When to Use RPC
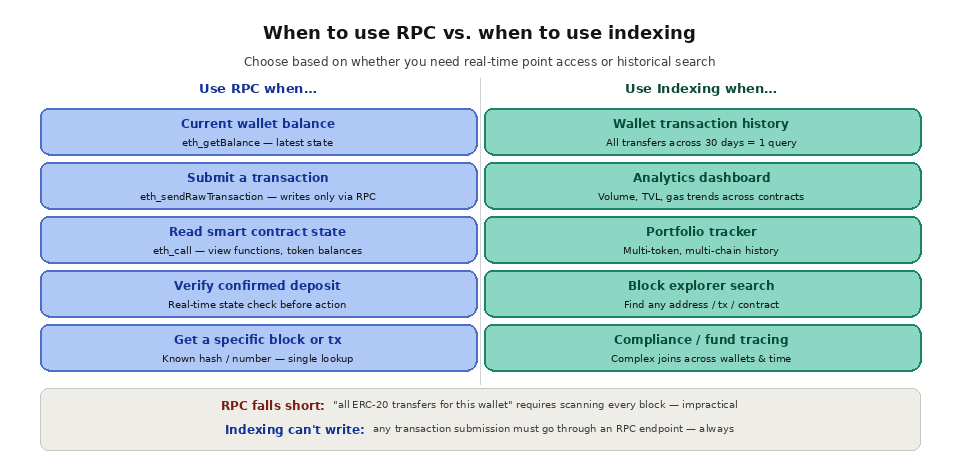
RPC is the right choice when your application needs to read or write specific, known data in real time. Checking a wallet's current ETH balance is a single "eth_getBalance" call. Submitting a signed transaction to the mempool requires "eth_sendRawTransaction." Reading the return value of a smart contract's view function uses "eth_call." These are all point queries where you know exactly what you want and the RPC method can return it directly.
RPC is also the only option for write operations. You cannot submit a transaction through an indexer. Indexers are read-only systems that process data after it has been committed to the chain. Whenever your application needs to send a transaction, approve a token, interact with a smart contract, or broadcast any state-changing operation, it must go through an RPC endpoint.
Real-time state verification is another RPC strength. When a DeFi protocol needs to check a user's collateral ratio before executing a liquidation, or when a bridge needs to verify a deposit has been confirmed, it queries the node's current state via RPC. The response reflects the latest canonical block, ensuring the data is as fresh as possible.
Where RPC falls short is any query that requires scanning, filtering, or aggregating data across multiple blocks or contracts. "Show me all ERC-20 transfers involving this address" requires iterating through every block and checking every transaction receipt, which is computationally impractical via RPC alone. "What is the total trading volume on Uniswap V3 in the last 24 hours" requires decoding and summing event logs from thousands of blocks across dozens of pool contracts. These are indexing problems.
When to Use Indexing
Indexing is essential whenever your application needs to search, filter, sort, or aggregate blockchain data. Portfolio trackers that display a user's complete transaction history across multiple tokens and chains depend on indexed data. Analytics dashboards that show trading volume, TVL trends, gas usage patterns, and protocol metrics are built entirely on indexed databases. Block explorers like Etherscan index the entire chain so users can search for any address, transaction, or contract.
Historical analysis is another core indexing use case. If a compliance team needs to trace the flow of funds through a series of wallets over six months, that requires querying indexed transaction data with complex joins and filters. If a research firm wants to analyze MEV extraction patterns across a year of Ethereum blocks, it needs a comprehensive index of transactions, traces, and event logs with the computational weight of those queries handled by a database, not a blockchain node.
Event-driven architectures also benefit from indexing. Instead of polling RPC endpoints to detect when a specific smart contract event fires, an indexer can continuously process new blocks and push matched events to your application in real time. This is more reliable than WebSocket subscriptions (which can disconnect and miss events) and more efficient than HTTP polling (which wastes requests on empty responses).
Using Both Together
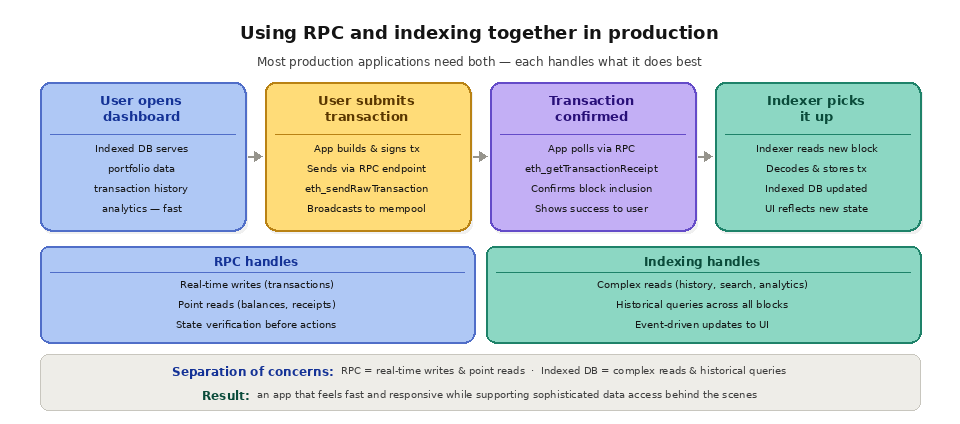
Most production blockchain applications use RPC and indexing in combination. The user-facing read experience is typically powered by indexed data: portfolio values, transaction histories, analytics dashboards, search results. When the user takes an action (sending a transaction, swapping tokens, minting an NFT), the application switches to RPC to submit the transaction to the network and confirm its inclusion. After the transaction is confirmed, the indexer picks it up from the new block and updates the database, which then reflects in the UI.
This architecture separates concerns cleanly. RPC handles real-time writes and point reads. Indexed databases handle complex reads and historical queries. The result is an application that feels fast and responsive to users while supporting sophisticated data access patterns behind the scenes.
What is the difference between RPC and indexing?
In short, an RPC endpoint answers direct questions about current or specific state, while blockchain indexing pre-processes the chain into a database you can search and aggregate. The table below lays out the practical differences side by side.
Aspect
RPC
Indexing
Access pattern
One request, one answer
Search, filter, and aggregate
Data freshness
Real time, latest block
Slight lag behind the chain tip
Historical depth
Needs an archive node
Stored and instantly queryable
Write support
Yes, the only way to write
No, read only
Setup effort
Low, call an endpoint
Higher, build or buy a pipeline
Best for
Live reads and transactions
Analytics, history, and search
Is an indexer faster than RPC for historical queries?
For anything that spans many blocks, yes. Asking an RPC node for a wallet's full history means scanning block by block, while an indexer has already decoded and stored that data, so the same question returns in a single fast query. The deeper the history, the larger the gap: see why querying blockchain data is hard and how real-time and historical data pull in different directions.
Query type
Best tool
Why
Current balance or state
RPC
Direct and real time
Submit a transaction
RPC
Only RPC can write
Wallet transaction history
Indexer
Needs search across blocks
Protocol volume or TVL
Indexer
Needs aggregation over time
Live new-block events
RPC or streaming
Low latency push
Can you build a blockchain indexer on top of RPC?
Yes, and almost every indexer does. An indexer reads the chain through RPC or a streaming feed, decodes each block, and writes structured rows into its own database. The hard parts are handling reorgs, retries, and gaps reliably, which is why many teams use a managed blockchain data streaming pipeline instead of hand-rolling RPC polling loops.
Does indexing replace RPC?
No. Indexing and RPC are complementary layers of the Web3 infrastructure stack. RPC remains the only way to submit transactions and read fresh state, while indexing powers search, history, and analytics. Production apps route writes and live reads to RPC and route complex reads to an index.
Frequently Asked Questions
Can you submit transactions through an indexer?
No. Indexers are read-only systems that process data after it is committed to the chain. Every transaction submission must go through an RPC endpoint.
Why is RPC slow for analytics queries?
RPC returns one piece of known data per call and cannot filter or aggregate across the chain. Answering an analytics question with RPC means making thousands of sequential calls and combining the results yourself, which is slow and expensive.
How fresh is indexed data compared to RPC?
Indexed data usually lags the chain tip by seconds to a few minutes, depending on the indexer. RPC reflects the latest canonical block, so for sub-second freshness you still read directly from a node.
Do you need an archive node for indexing?
To backfill deep history you need archive data, either from an archive node or a backfill pipeline. See full node vs archive node for the distinction.
Is The Graph an indexer or an RPC provider?
The Graph is an indexing protocol. Its own indexers read the chain through RPC and expose the processed result as queryable subgraphs. It cannot submit transactions or serve sub-second real-time data on its own.
How Quicknode Supports Both
Quicknode provides infrastructure for both sides of this equation. The Core API delivers globally distributed, low-latency RPC access across 80+ chains, handling real-time reads and transaction submissions with 99.99% uptime and response times 2.5x faster than competitors. Enhanced API methods reduce the number of individual RPC calls needed for common operations like fetching token balances or NFT collections.
Quicknode Streams bridges the gap between RPC and indexing by providing a push-based data pipeline that delivers raw or filtered blockchain data directly to your database, data warehouse, or webhook. Instead of building and maintaining custom RPC polling infrastructure to feed your indexer, you configure a Stream and Quicknode handles data extraction, filtering, delivery, reorg correction, and retry logic. Streams supports both real-time streaming and historical backfills, so you can populate your index from genesis and keep it current with a single tool. For teams that need to build their own indexer, Quicknode publishes a step-by-step guide showing how to create a complete blockchain indexer backed by PostgreSQL using Streams.