Answers>Learn about blockchain security fundamentals>What is a blockchain reorg?
What is a blockchain reorg?
// Tags
blockchain reorgchain reorganization
TL;DR: A blockchain reorg (short for reorganization) occurs when the network's canonical chain changes and blocks that were previously considered part of the main chain are replaced by a different set of blocks. This can cause confirmed transactions to disappear, transaction ordering to change, and application state to become inconsistent. Reorgs happen naturally on most blockchains due to network latency and concurrent block production, but deep reorgs can also result from attacks or software bugs. Understanding reorgs is critical for any developer building applications that depend on confirmed blockchain data, because failing to account for reorgs can lead to double-spend vulnerabilities, phantom transactions, and corrupted databases.
The Simple Explanation
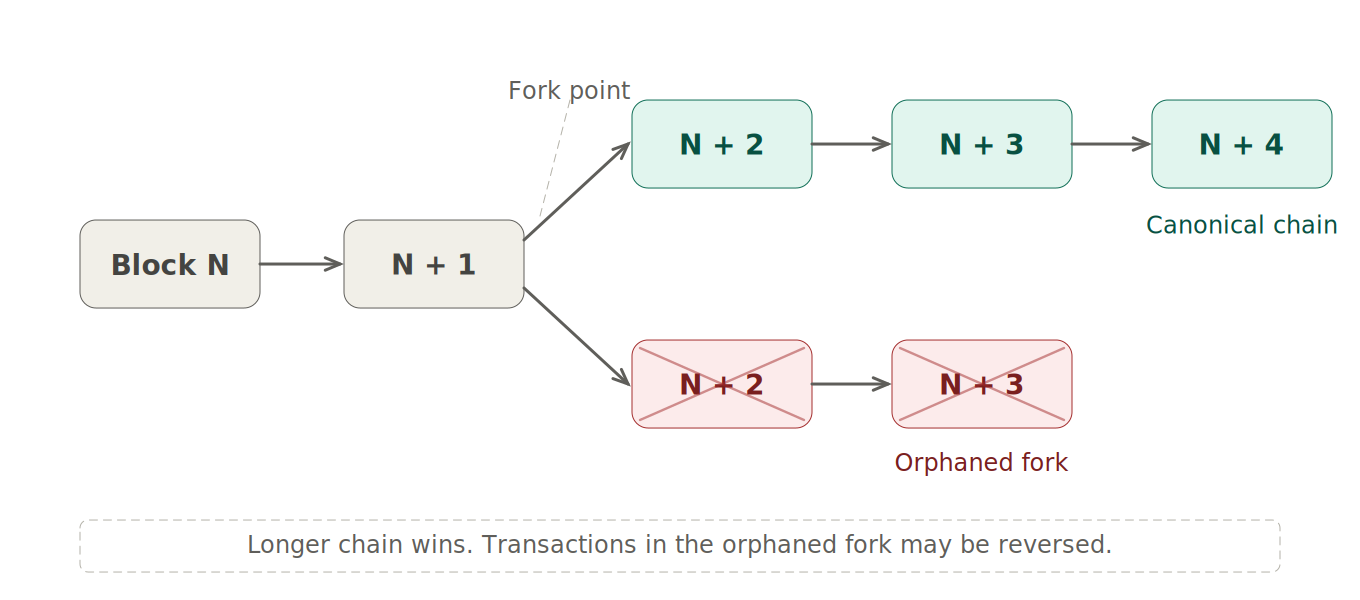
Think of a blockchain as a single path through a forest, where each step is a block. Under normal conditions, everyone follows the same path. But occasionally, two trailblazers find different routes at the same time, and for a brief period, two valid paths exist simultaneously. The network eventually decides which path is correct (usually the one that extends further first), and everyone switches to that path. Anyone who was following the other path has to backtrack and switch over.
When this switch happens, that is a reorg. The blocks on the abandoned path are discarded, and the blocks on the winning path become the canonical chain. Any transactions that were in the abandoned blocks may or may not appear in the winning chain's blocks. Some transactions might land in both paths at the same position. Others might appear in one but not the other. A few might be dropped entirely if they conflict with transactions in the winning chain.
For most end users, shallow reorgs (one or two blocks deep) happen frequently and invisibly. Your wallet might briefly show a transaction as confirmed, then show it as pending again for a few seconds before it re-confirms in the new canonical block. You probably would not even notice. But for applications that process blockchain data at scale, even a one-block reorg means records that were already written to your database based on the old blocks are now incorrect and need to be corrected.
How Reorgs Happen
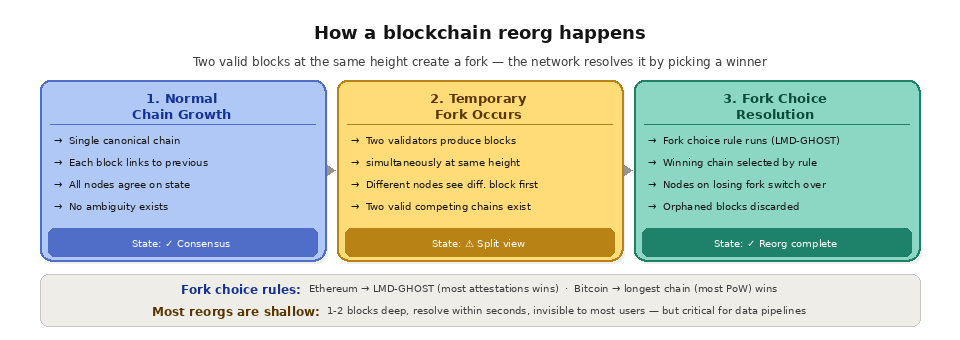
The most common cause of reorgs is natural network latency. When two validators produce valid blocks at approximately the same time (within the same slot or at the same block height), different parts of the network may temporarily adopt different blocks. Node A might see Block X first and consider it canonical, while Node B sees Block Y first. Both blocks are valid according to consensus rules, but only one can ultimately be part of the main chain.
The network resolves this ambiguity through its fork choice rule. On Ethereum, the fork choice rule (LMD-GHOST) selects the chain supported by the most validator attestations. On Bitcoin, the longest chain (most accumulated proof of work) wins. Regardless of the specific rule, the result is the same: one fork is adopted as canonical, and the other is abandoned. Nodes that were following the abandoned fork detect the switch, roll back the orphaned blocks, and adopt the winning chain.
On Proof of Work chains like Bitcoin, reorgs are relatively common because the mining process is inherently probabilistic. Two miners can find valid blocks at nearly the same time, creating a temporary fork that resolves within one or two blocks. One-block reorgs on Bitcoin happen regularly and are considered a normal part of the network's operation. Deeper reorgs are rare under honest conditions but become possible if an attacker controls a significant portion of the network's hash power (the basis of a 51% attack).
On Ethereum's Proof of Stake system, the slot-based block production model reduces the frequency of natural reorgs because each slot has a designated proposer. However, reorgs can still occur if a proposer's block arrives late (due to network latency) and the next proposer builds on the previous canonical block instead. Missed slots, where the designated proposer fails to produce a block, can also create conditions for short reorgs when multiple validators build on different views of the chain.
Types of Reorgs
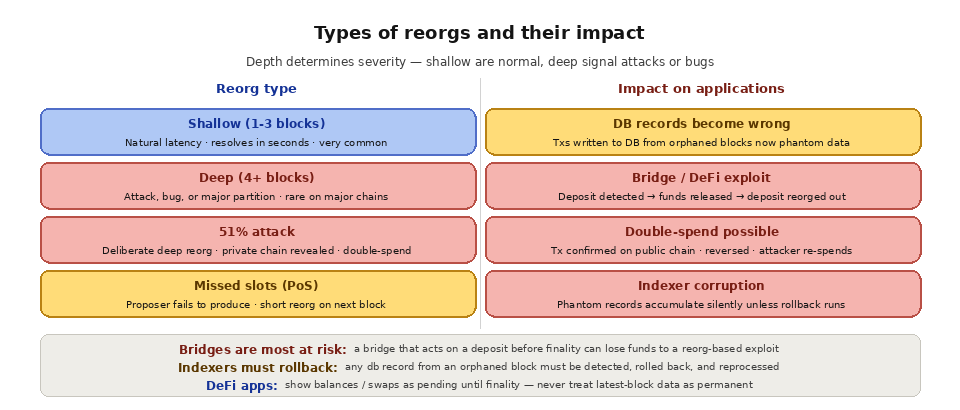
Shallow reorgs are one to three blocks deep and occur naturally on most blockchains. They are a normal consequence of distributed consensus and resolve themselves within seconds. Most applications can handle shallow reorgs by waiting a few additional block confirmations before treating data as final.
Deep reorgs are more than three blocks deep and are usually a sign of something abnormal: a deliberate attack, a consensus bug, or a significant network partition. A deep reorg on a major chain is a serious event because it can reverse transactions that users and applications had already considered confirmed. Deep reorgs on smaller chains with less security (lower hash power or staked value) are more common and have been used to execute double-spend attacks.
A 51% attack (or 34% attack on some PoS chains) is the deliberate creation of a deep reorg. An attacker with majority consensus power mines or validates a private chain that differs from the public one, then reveals it to the network. Because the attacker's chain is longer (or has more attestations), the network adopts it as canonical, orphaning the public chain's recent blocks. This allows the attacker to reverse transactions on the abandoned chain, potentially double-spending funds that were previously sent and confirmed.
Impact on Applications
For applications that process blockchain data, reorgs present a data consistency challenge. If your application writes transaction records to a database as soon as they appear in a block, a reorg means some of those records are now based on blocks that no longer exist. The transactions might still appear in the new canonical blocks (just at a different position or in a different block number), or they might be missing entirely.
DeFi applications are especially vulnerable. If a DEX aggregator shows a swap as confirmed and updates the user's portfolio, but a reorg removes that swap from the canonical chain, the portfolio is now wrong. If a bridge detects a deposit on the source chain and releases funds on the destination chain, but a reorg removes the deposit, the bridge has issued funds against a transaction that no longer exists. This is one of the primary attack vectors against cross-chain bridges.
Indexers and data pipelines must detect reorgs, identify which blocks were abandoned, roll back any records derived from those blocks, and reprocess the correct canonical blocks. Without this logic, the indexed database accumulates phantom records from orphaned blocks, creating inconsistencies that grow over time and corrupt downstream analytics, balances, and transaction histories.
How to Handle Reorgs
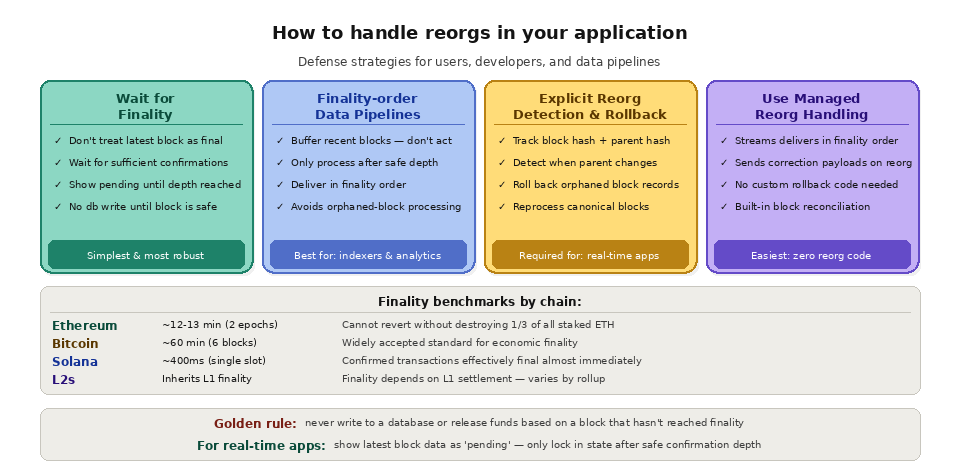
The simplest defense against reorgs is to wait for finality before treating data as confirmed. On Ethereum, finality occurs after two epochs (roughly 12-13 minutes), after which blocks cannot be reverted without destroying at least one-third of all staked ETH. On Bitcoin, six confirmations (approximately 60 minutes) is the widely accepted standard for economic finality. On Solana, single-slot finality means confirmed transactions are effectively final within about 400 milliseconds.
For applications that cannot afford to wait for full finality (because users expect faster feedback), the best practice is to show data as "unconfirmed" or "pending" until sufficient confirmations have passed, and to implement rollback logic that gracefully handles the case where a recently confirmed transaction is reversed by a reorg.
Data pipelines should process blocks in finality order whenever possible. Instead of ingesting blocks the moment they appear at the chain tip (which risks processing blocks that may later be orphaned), pipelines should buffer recent blocks and only process them after they have reached a safe confirmation depth. For real-time use cases where buffering is not acceptable, the pipeline must include explicit reorg detection and rollback mechanisms.
What is the difference between a reorg and a fork?
Reorgs and forks are related but not the same thing. A fork is any point where the chain splits into two competing branches, which can be temporary (two valid blocks at the same height) or permanent (a protocol upgrade that creates a new chain). A reorg is specifically what happens when nodes abandon one branch and switch to another after a temporary fork resolves. In other words, a temporary fork is the cause and a reorg is the consequence on the nodes that backed the losing branch.
Aspect
Reorg
Fork
Definition
Nodes replace canonical blocks with a competing branch
The chain splits into two or more branches
Trigger
A temporary fork resolves in favor of another branch
Concurrent blocks, a bug, or a protocol upgrade
Permanence
Always temporary; one branch is discarded
Can be temporary or permanent
Effect on data
Confirmed transactions may move or disappear
May create a separate, lasting chain
For a deeper look at the different split types, see what a chain fork is. Reorgs are also closely tied to transaction ordering, because the order of transactions can change when the canonical branch switches.
How many confirmations protect against a reorg?
The safe number of confirmations depends on the chain's consensus design and how much value is at stake. More confirmations mean a deeper reorg would be required to reverse your transaction, which becomes exponentially more expensive for an attacker. The table below summarizes common guidance for treating data as final.
Chain
Common finality threshold
Approx. wall-clock time
Bitcoin
6 confirmations
~60 minutes
Ethereum
2 epochs (finalized)
~12 to 13 minutes
Solana
Single-slot finality
~400 milliseconds
Smaller PoW chains
Many more confirmations
Varies, higher reorg risk
Waiting for blockchain finality is the strongest protection, while smaller or less secure networks need deeper confirmation depths because their reorg risk is higher. Reliable infrastructure also matters here: see why node reliability matters for consistent reorg-aware data.
Can a blockchain reorg be an attack?
Most reorgs are harmless and resolve within a block or two, but a deliberately engineered deep reorg is an attack. By privately building a competing chain and then releasing it, an attacker with enough consensus power can orphan recent blocks and reverse transactions that looked confirmed, which is the mechanism behind double-spend and 51% attacks. Reorgs also overlap with profit extraction strategies, so understanding what MEV is and reviewing common blockchain failure modes helps teams design systems that fail safely when a reorg is malicious rather than natural.
Frequently Asked Questions
Are blockchain reorgs normal?
Shallow reorgs of one to three blocks are a normal part of distributed consensus and happen routinely, especially on Proof of Work chains. They usually resolve within seconds and most users never notice. Deep reorgs, on the other hand, are abnormal and often signal an attack or a bug.
Do confirmed transactions disappear during a reorg?
They can. A transaction in an orphaned block may reappear in the new canonical chain at a different position, or it may be dropped entirely if it conflicts with the winning branch. This is why applications should wait for sufficient confirmations before treating a transaction as final.
Which blockchains have the most reorgs?
Proof of Work chains and smaller networks with lower hash power or staked value experience reorgs more frequently. Bitcoin sees occasional one-block reorgs, while chains with weaker security are more exposed to deeper, potentially malicious reorgs.
How do indexers handle reorgs?
A reorg-aware indexer detects the fork, identifies which blocks were abandoned, rolls back any records derived from them, and reprocesses the new canonical blocks. Without this logic, the database accumulates phantom records that corrupt balances and analytics over time.
Does waiting for finality prevent reorg problems?
Yes. Once a block reaches finality it cannot be reverted without an extreme economic cost, so data tied to finalized blocks is safe from reorgs. The tradeoff is latency, which is why some applications display unconfirmed data while reserving irreversible actions for finalized data.
How Quicknode Handles Reorgs
Quicknode Streams is designed with reorg handling built into its core architecture. Streams delivers blockchain data in finality order, meaning blocks are processed and delivered only after they have reached a safe confirmation depth on the network. When a reorg does occur, Streams automatically detects the fork, identifies which delivered blocks are no longer canonical, and sends correction payloads to your destination so your data stays consistent with the true state of the chain.
This built-in reorg handling eliminates one of the most complex engineering challenges in blockchain data processing. Instead of building custom reorg detection, rollback logic, and block reconciliation into your pipeline, you configure a Stream and Quicknode handles the rest. Whether you are building an indexer, an analytics platform, or a real-time monitoring system, Streams guarantees that the data in your destination matches the canonical chain, even during network reorganizations.
Quicknode's Core API also supports querying both the latest and finalized block data across supported networks, letting your application choose the confirmation level appropriate for each use case. Display the latest block to users who want instant feedback, but rely on finalized block data for any logic that involves financial decisions or irreversible actions.